
MaxRequestWorkersによってロードバランサーのEC2ヘルスチェックがタイムアウトするようになったのでCloudWatchで監視するようにしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
いわさです。
先日、Apacheで構成されるWebサーバーがヘルスチェックに失敗して、Webサーバーへアクセスできなくなってしまいました。
Webサーバーのログを確認してみると、AH00161エラーが確認されました。
原因として、Apacheで設定しているMaxRequestWorkers値に同時処理可能な接続の最大数を設定するのですが、サーバーサイドアプリケーション上でボトルネックになっている処理があり、処理中のプロセスが増え続け上限に達していました。
MaxRequestWorkersに達した場合は、ListenBacklogで設定されるキューで待つことになります。
それによってヘルスチェックがタイムアウトを起こしていました。
MPM(マルチプロセッシングモジュール)はpreforkを使っており、MaxRequestWorkersの設定変更が可能なのですが、設定値の見直しにあわせてそもそも平時のプロセス数について改めて確認することにしました。
preforkの場合はプロセス数を監視すればどのラインまで達しているのかが判断出来るので、CloudWatchで監視してみようかと思います。
※ MaxRequestWorkersにどういう値を設定するのが適切なのか、試算方法については本記事では触れません。
処理時間がかかるWebページを作成
単純なスリープ有りのスクリプトを使ってみます。
<?php sleep(30); ?> hoge sleep.
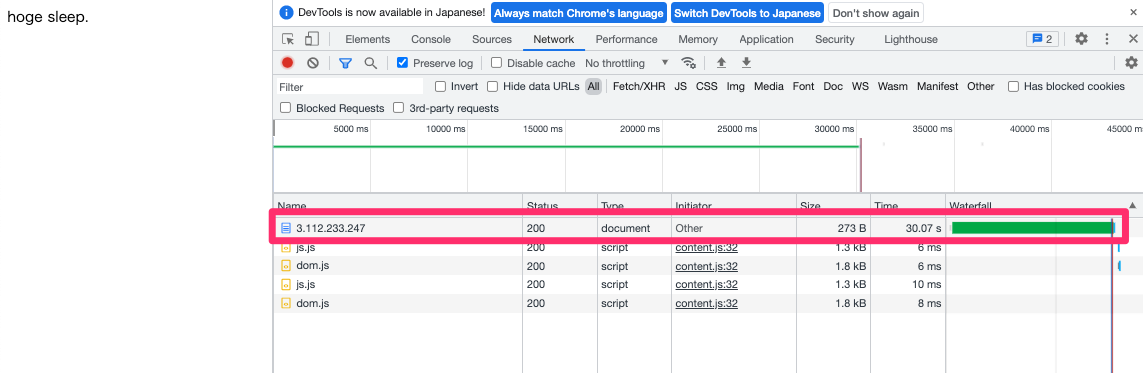
ボトルネックになる部分を作成出来たので、あとはMaxRequestWorkersの設定を行っていきます。
MPMがpreforkであることを確認出来たら、設定ファイルを作成しApacheを再起動します。
[ec2-user@ip-172-31-37-50 html]$ httpd -V
Server version: Apache/2.4.48 ()
Server built: Jun 25 2021 18:53:37
Server's Module Magic Number: 20120211:105
Server loaded: APR 1.7.0, APR-UTIL 1.6.1
Compiled using: APR 1.6.3, APR-UTIL 1.6.1
Architecture: 64-bit
Server MPM: prefork
threaded: no
forked: yes (variable process count)
Server compiled with....
-D APR_HAS_SENDFILE
-D APR_HAS_MMAP
-D APR_HAVE_IPV6 (IPv4-mapped addresses enabled)
-D APR_USE_SYSVSEM_SERIALIZE
-D APR_USE_PTHREAD_SERIALIZE
-D SINGLE_LISTEN_UNSERIALIZED_ACCEPT
-D APR_HAS_OTHER_CHILD
-D AP_HAVE_RELIABLE_PIPED_LOGS
-D DYNAMIC_MODULE_LIMIT=256
-D HTTPD_ROOT="/etc/httpd"
-D SUEXEC_BIN="/usr/sbin/suexec"
-D DEFAULT_PIDLOG="/run/httpd/httpd.pid"
-D DEFAULT_SCOREBOARD="logs/apache_runtime_status"
-D DEFAULT_ERRORLOG="logs/error_log"
-D AP_TYPES_CONFIG_FILE="conf/mime.types"
-D SERVER_CONFIG_FILE="conf/httpd.conf"
[ec2-user@ip-172-31-37-50 html]$
[ec2-user@ip-172-31-37-50 html]$ sudo vi /etc/httpd/conf.d/prefork.conf
<IfModule mpm_prefork_module>
StartServers 3
MinSpareServers 1
MaxSpareServers 5
MaxRequestWorkers 30
ListenBacklog 10
</IfModule>
[ec2-user@ip-172-31-37-50 html]$ sudo service httpd restart
preforkの場合はプロセス数をウォッチ出来れば良いですが、それ以外の場合はスレッドについて考慮が必要です。
JMeterでローカルから負荷を発生させる
適当な負荷ツールでいくつかHTTPリクエストを発生させます。
私はJMeterを使用しましたが、使い方については本記事では触れません。


一旦EC2のコンソール上で接続数、プロセス数、バックログキューの数値を確認してみます。
以下は負荷をかける前です。
[ec2-user@ip-172-31-37-50 html]$ netstat -an |grep :80 |wc -l;ps aux | grep httpd | wc -l;ss -tnl | grep .80 | awk '{print $2}'
1
7
0
以下は負荷がかかっている状態です。
[ec2-user@ip-172-31-37-50 html]$ netstat -an |grep :80 |wc -l;ps aux | grep httpd | wc -l;ss -tnl | grep .80 | awk '{print $2}'
43
32
11
プロセス数についてhttpdでgrepしているだけなのでgrepと親プロセスで+2されていますが、負荷がかかる前はMaxSpareServers+2で待機しており、負荷がかかっている最中は子プロセスがMaxRequestWorkers+2以上に増えていないですね。
また、バックログキューへMaxRequestWorkersを超過した分が、ListenBacklogを上限としてキューイングされています。
上記をさらに超過した分は、接続が確立出来ていないですね。
エラーログでAH00161を確認することも出来ました。
[ec2-user@ip-172-31-37-50 html]$ cat /var/log/httpd/error_log | grep AH00161 [Sun Nov 07 22:07:07.264345 2021] [mpm_prefork:error] [pid 3882] AH00161: server reached MaxRequestWorkers setting, consider raising the MaxRequestWorkers setting [Sun Nov 07 22:19:23.756599 2021] [mpm_prefork:error] [pid 4616] AH00161: server reached MaxRequestWorkers setting, consider raising the MaxRequestWorkers setting
レスポンスとしてはタイムアウトが発生しているので、ヘルスチェックが失敗した時と同じ状況になっているんじゃないかと思います。
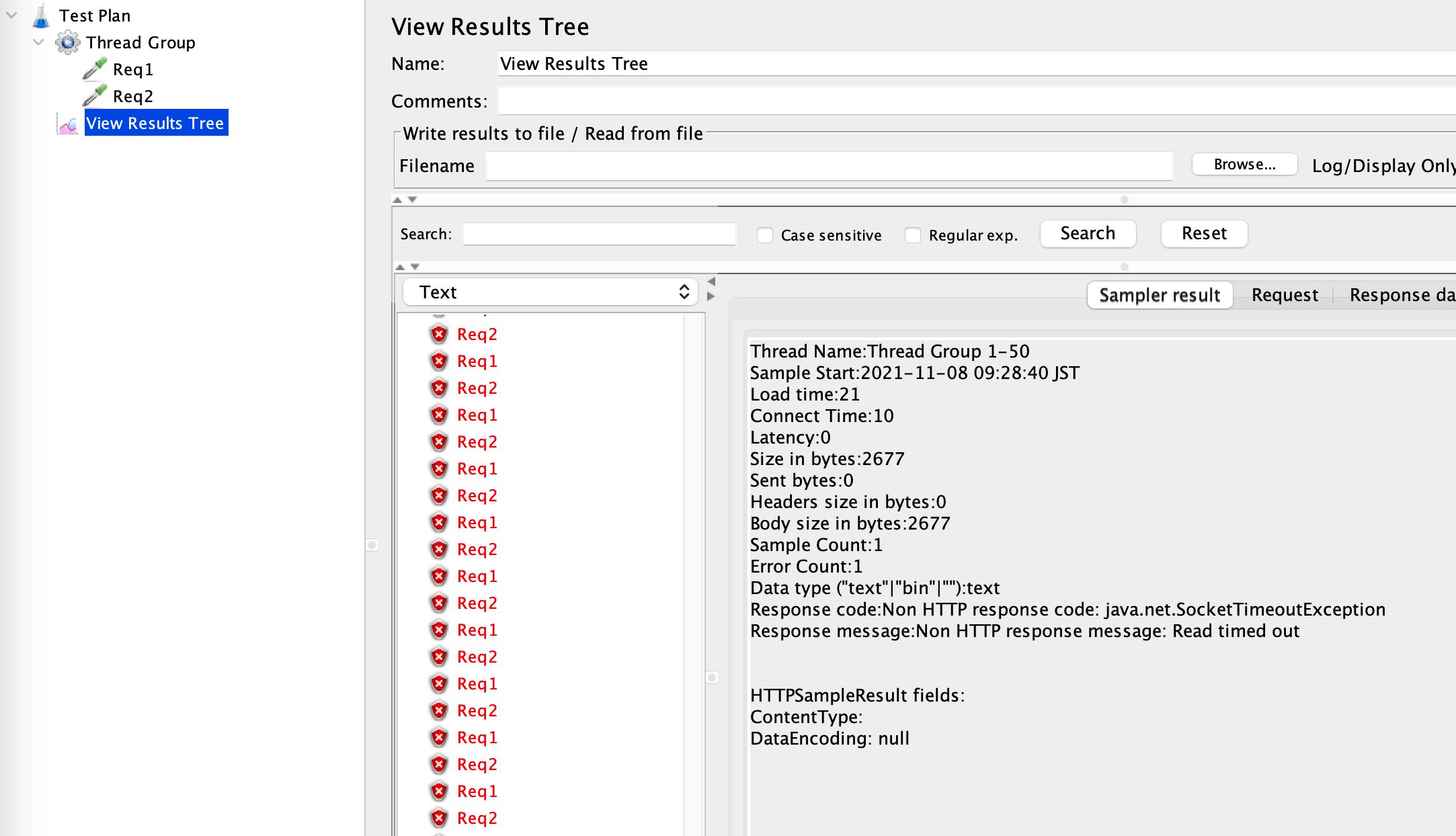
ここまでで、やはりプロセス数を監視出来ればMaxRequestWorkersの見直しやスケールアップに活かすことが出来そうです。
アクセススパイク時の挙動をCloudWatchで確認
プロセスの監視自体は以下の記事のとおりセットアップします。
メトリクスの収集時間については1秒単位にしてみます。
{
"metrics": {
"metrics_collected": {
"procstat": [
{
"exe": "httpd",
"measurement": [
"pid_count"
],
"metrics_collection_interval": 1
}
]
}
}
}
まずは、10件で負荷をかけてみます。

先程、コンソールで確認した時と同じように、10件前後になりました。
ちなみに、1秒ごとの値の報告はされていそうですがが、コンソールで確認出来るまで少し10秒くらい?時間がかかりました。
次は50件で負荷をかけてみます。

先程の検証結果と同様に30件前後で止まりましたね。
検証中のMaxの30件前後になっている状態は処理がキュー待ちになっている可能性があり、もともとの事象であるロードバランサーでのヘルスチェックタイムアウトが発生する状態と考えられます。
まとめ
本日はCloudWatchからMaxRequestWorkersへの到達状況を監視できるか確認してみました。
監視自体は出来ますね。
ただ、ヘルスチェックでUnhealthyと判断されるのも難しいほどの瞬間的な上昇の場合はオートスケールの類いだと追いつかなそうなので、予め試算して設定した上で、この監視機能は使うとしても傾向分析に使うくらいが良い気がしました。
また、アラームを設定して到達度合いを検知出来るようにしておくと、利用者の増加などによっていつのまにか設定値を見直すべきタイミングになっていたなどに気づきやすくなるかもしれません。
ちなみに、今回は検証のためにカスタムメトリクスを使用しましたが、実際に利用する際は料金や保存期間などの高解像度カスタムメトリクスのメリット・デメリットを把握した上での導入判断も必要になりそうです。








